배틀그라운드의 유저 플레이 데이터 수집 프로세스를 만들어낸 입장에서 이를 활용한 기계학습도 해보고 싶어 진행해 보는 프로젝트이다. 필자가 알고 있는 게이머와 관련된 지식을 데이터적으로 확인 및 검증해 보는 시간을 가져보는 것이 좋은 것 같아 간단한 클러스터링을 포함한 검증의 시간을 가져보기로 한다.
시작하기에 앞서
Richard Bartle에 의해 정의된 게이머의 4가지 유형은 아래의 그림과 같다.

상기 지표에서 의미하는 바를 간단하게 설명하고, 이를 배틀그라운드 게임에 대입시켜 생각해보자.
1. Killers
활동적이고 플레이어 간의 상호작용을 중시하는 게이머. 주도적으로 다른 플레이어와 분쟁을 하고, 싸움과 관련된 콘텐츠를 즐기는 플레이어가 이에 해당한다. 1:1 대전게임인 철권이 대표적인 예로 뽑힐 것이다.
2. Achievers
활동적이지만 플레이어보다는 월드/게임의 상호작용을 중시하는 게이머. 업적을 달성하고, 레벨업을 하기 위해 퀘스트를 진행하고, 성장을 위해 사이드 퀘스트를 진행하는 등. RPG 게임을 처음 시작하면 대부분의 플레이어가 Achievers가 되도록 설계되어 있다는 특징을 가진다.
3. Socialisers
활동적이기보다는 유저들하고의 상호작용을 중시하는 게이머. 채팅을 하거나 '같이 하는' 것에 더 가치를 두는 플레이어가 이에 해당될 것 같다.
4. Explorers
월드하고의 상호작용을 중시하는 플레이어. 최고 난이도로 클리어하거나 아무도 해보지 못한 것들을 찾아내는 것 등, 항상 새로운 것을 탐험하는 것을 즐기는 유저들이 이에 해당될 것이다.
필자는 상기의 지표를 좋아한다. 일례로 대외활동을 진행하며 만든 여러 미니게임을 만들기에 앞서 필자의 게임 성향을 파악하기 위해서도 상기의 지표를 활용하였다. 관련 포스팅은 아래의 URL를 참고하시라.
https://songmin9813.tistory.com/3
SWM에서 게임 개발로 살아남기(2. 게임 기획)
시리즈물로 제작 중입니다. 이전 내용과 이어집니다. https://songmin9813.tistory.com/2(1. 개요) 2. 게임 기획 1. 내 게임 타입 훑어보기 기술적인 문제도 문제였지만 특히나 나에게 다가온 가장 큰 허들
songmin9813.tistory.com
그렇다면 기존에 진행했던 배틀그라운드의 유저 데이터도 이를 따라갈까?라는 생각이 문득 들게 되었다. 이를 조금 더 구체적으로 명시하면 아래의 질문과도 같다.
Q. K-Means Clustering의 K값을 4로 전제하면 상기의 지표와 같은 결과가 나올까?
이러한 질문을 시작으로 게임 데이터를 기준으로 차원 압축과 비지도 학습을 진행해 보고, K를 4로 했을 때와 다른 방법론을 사용했을 때의 차이점을 시각적으로 분석해 보는 시간을 가져보도록 한다.
데이터 전처리
빠르게 2월 10일을 기준으로 13일 전까지의 데이터를 수집해 온 뒤, AI 플레이어를 제외한 데이터프레임을 만들었다.

약 52만 개의 유저 데이터가 남았고, 존재하는 열은 아래의 열 정보와 같았다.
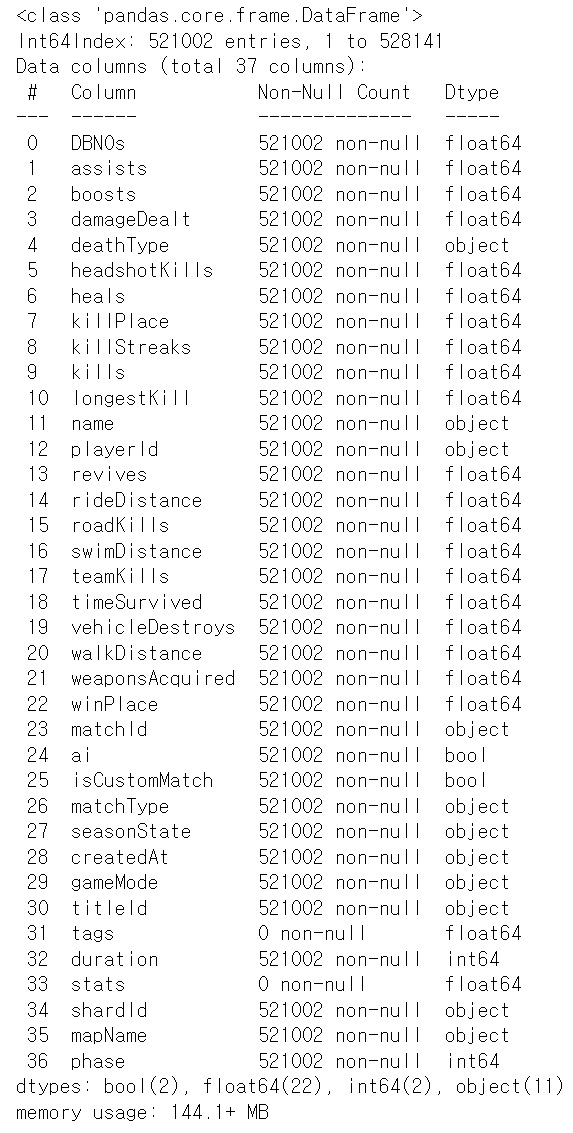
우리는 표준화를 진행할 것이기 때문에, 수치형 변수들만을 남겨야 하는 것이 첫 번째 목표. 명목형 데이터인 object 타입과 순서로써 존재하는 phase, 그리고 bool 타입 등을 전부 제거하고 난 뒤의 남겨진 정보들은 아래의 테이블 정보과 같다.
그리고 명목형 데이터 중 개인적으로 중요하다고 생각되는 플랫폼(shardId), 맵(mapName), 솔로/듀오/스쿼드 정보(gameMode)은 one-hot encoding을 통하여 살려둔 채로 표준화를 진행하기로 하였다.
drop_cols=['killPlace','deathType','name','playerId','winPlace','matchId','ai','isCustomMatch','matchType','seasonState','createdAt','gameMode','titleId','tags','stats','shardId','mapName']
# 자체 판단 하 사라지는 데이터들
# shardId와 mapName, gameMode에 대한 one hot encoding 후 concat
df_result = pd.concat([player_df.drop(drop_cols, axis=1),pd.get_dummies(player_df[['mapName','gameMode','shardId']])],axis=1)
df_result

이제 표준화를 진행한 데이터프레임을 새로 만들어보도록 하자.
df_standardized = (df_result - df_result.mean()) / np.std(df_result)
# 표준화 가보자고

다음 게시글에서는 PCA의 정의와 함께 이를 진행한 결과를 알아보고, 시간이 된다면 클러스터링을 진행한 결과도 도출해내보도록 한다.
💡 정규화가 아닌 표준화를 진행하는 이유?
차원 압축을 위해 주성분 분석(PCA)을 진행할 것이기 때문에, 분산값을 더욱 돋보이게 표현할 수 있는 표준화를 진행하기로 마음먹었다.
'개발 > 데이터 분석' 카테고리의 다른 글
| 4종류의 게이머가 존재한다고? - 3. Clustering 및 분석 결과 (0) | 2023.02.16 |
|---|---|
| 4종류의 게이머가 존재한다고? - 2. PCA (0) | 2023.02.14 |
| 우리가 분석을 하며 놓치고 있는 것들 - 회귀분석 (0) | 2023.02.04 |
| Kakao 버전 배틀그라운드 유저 데이터 분석해보기[통합] (2) | 2023.01.25 |
| [Python/Analytic] 배틀그라운드 유저 데이터 분석 코드 공유 (8) | 2023.01.23 |