본 게시글은 필자가 배그 데이터 시각화 프로젝트를 진행하며 작성한 데이터 가공 코드를 자동화버전으로 재가공하여 배포하는 배포용 코드이다.
Python으로 작성되었으며, 필자의 가공이 들어간 'phase', 'ai' 정보를 제외한 모든 정보는 아래의 PUBG Open API 사이트에서 확인해 볼 수도 있다.
https://developer.pubg.com/(PUBG Open API)
개인 전용 토큰 키 발행 필수
해당 코드를 어떠한 생각으로 짰는지 궁금하다면 이전의 시리즈들을 참고하면 좋을 것 같다.
https://songmin9813.tistory.com/43(1. 프로세스 수립)
https://songmin9813.tistory.com/44(2. 데이터 인사이트 및 추출)
https://songmin9813.tistory.com/49(3. 데이터 가공)
https://songmin9813.tistory.com/50(4. 데이터 추가 가공 및 시각화)
인터넷을 통해 얻어간 내용들이 많기에 필자 또한 다른 개발자들을 위해 코드를 다듬어 배포해본다. 아마 데이터의 가공보다는 데이터의 시각화를 연습하기 위한 분석가들에게 더 필요한 코드이지 않을까 싶다.
개발도 겸해서 하고 싶으면 그냥 직접 코드 짜봐라~
아래는 필요한 라이브러리와 함수 선언부이다.
import requests
import json
import time
import datetime
import pandas as pd
import re
token='' # 자신이 생성한 Token을 여기에 입력
platform='steam' # steam, kakao, console 중 택 1
#API를 사용한 크롤링 함수 작성
#사용 라이브러리 및 함수 선언
def call(day, platform):
headers = {'accept': 'application/vnd.api+json',
'Authorization': 'Bearer '+token,
}
response = requests.get('https://api.pubg.com/shards/'+platform+'/samples?filter[createdAt-start]='+day,
headers=headers,)
return response.json()
def make_day(previous_day):
return (datetime.datetime.now()-datetime.timedelta(days=previous_day)).strftime("%Y-%m-%dT00%%3A00%%3A00Z")
def get_match(match_id, platform):
headers = {'accept': 'application/vnd.api+json',}
response = requests.get('https://api.pubg.com/shards/'+platform+'/matches/'+match_id, headers=headers)
return response.json()
# 파라모는 사녹, 태이고는 에란겔 자기장 정보 따라갔음
# 가변 자기장은 수식에서 제외(특정 인원 미만일 시 자기장 카운트 시작되는 기능)
def map_to_phase(mapName, duration):
if mapName=='Savage_Main' or mapName=='Chimera_Main': # 사녹 파라모
if 0<=duration<450:
return 1
elif duration<690:
return 2
elif duration<900:
return 3
elif duration<1080:
return 4
elif duration<1185:
return 5
elif duration<1290:
return 6
elif duration<1375:
return 7
elif duration<1460:
return 8
else:
return 9
elif mapName=='Desert_Main': # 미라마
if 0<=duration<720:
return 1
elif duration<1060:
return 2
elif duration<1300:
return 3
elif duration<1480:
return 4
elif duration<1640:
return 5
elif duration<1760:
return 6
elif duration<1880:
return 7
elif duration<1970:
return 8
else:
return 9
elif mapName=='DihorOtok_Main': # 비켄디
if 0<=duration<630:
return 1
elif duration<870:
return 2
elif duration<1050:
return 3
elif duration<1220:
return 4
elif duration<1370:
return 5
elif duration<1490:
return 6
elif duration<1610:
return 7
elif duration<1730:
return 8
else:
return 9
else: # 에란겔 태이고 데스턴
if 0<=duration<690:
return 1
elif duration<990:
return 2
elif duration<1210:
return 3
elif duration<1390:
return 4
elif duration<1550:
return 5
elif duration<1670:
return 6
elif duration<1770:
return 7
elif duration<1860:
return 8
else:
return 9
가장 위 token부에 자신이 사이트에서 발급받은 token 값을 그대로 넣어주면 되고,
samples 데이터에 존재하는 3개의 항목인 steam(스팀 버전), kakao(카카오 버전), console(엑박 및 플스 버전)에 따라
platform 변수에 3개 중 하나를 넣어주면 된다.
아래는 선언된 함수를 바탕으로 실제 작동되는 구현부이다.
# 데이터 수집
data=[]
for i in range(1,14):
result=call(make_day(i),platform)
for value in result['data']['relationships']['matches']['data']:
data.append(value['id'])
print(str(i)+"날 전 추출 완료")
time.sleep(7)
match_table=[] # 실제로 많은 json이 저장될 match_table
for value in data:
match_table.append(get_match(value, platform))
# first : 유저 속성 데이터
# raw data 기준으로 실제 테이블 작성. concat의 뼈대 테이블 생성
temp=pd.DataFrame(match_table[0]['included'])
df=temp[temp['type']=='participant']['attributes'].apply(lambda x:x['stats'])
first=pd.DataFrame([*df])
first['matchId']=match_table[0]['data']['id']
print(first.head())
for i in range(1,len(match_table)):
if i%500==0:
print(i,'번 째 진행중입니다.')
temp=pd.DataFrame(match_table[i]['included'])
df=temp[temp['type']=='participant']['attributes'].apply(lambda x:x['stats'])
before=pd.DataFrame([*df])
before['matchId']=match_table[i]['data']['id']
first=pd.concat([first,before])
# ai 정보 추가
name=re.compile(r'ai.\d\d\d')
first['ai']=list(map(lambda x:name.search(x)!=None,list(first['playerId'])))
# 유저속성 코드 작성 완료. map 정보 일부 따오기 코드
pd.DataFrame([match_table[0]['data']['attributes']])
second=pd.DataFrame([match_table[0]['data']['attributes']])
second['matchId']=match_table[0]['data']['id']
print(second.head())
for i in range(1,len(match_table)):
if i%500==0:
print(i,'번 째 진행중입니다.')
before=pd.DataFrame([match_table[i]['data']['attributes']])
before['matchId']=match_table[i]['data']['id']
second=pd.concat([second,before])
# first table, second table을 저장할 필요가 있을까? 일단은 보류임
# 필요하면 이곳에 코드를 작성
# duration 정보를 second에 추가하고 merge 후 csv 형태로 저장하여야 함
merged_table=pd.merge(first,second,on='matchId')
merged_table['phase']=list(map(lambda x,y:map_to_phase(x,y),merged_table['mapName'],merged_table['timeSurvived']))
print(merged_table.info())
merged_table.to_csv('merged_attributes_'+platform+'.csv')
그리고 아래의 파일은 상기 두 코드를 결합한 python 파일이다. 필자는 Jupyter Notebook으로 작업환경을 구성했기에 단순 py 파일로만 변환을 하였으니 관련 이슈가 발생한다면 직접 찾아가 보며 고치는 것을 권장한다.
함수 실행 후 상기 구현부를 실행하게 되면 상당히 많은 리소스를 잡아먹는다. 실제로 2~300MB는 거뜬히 넘는 파일을 하나의 변수에 담는 작업이 포함되어있고, 이러한 이유로 최소 16GB 이상의 RAM을 가지고 있는 개발자에게만 해당 코드를 실행해볼 것을 권장한다.
steam 플랫폼 기준 위의 코드를 온전히 실행하게 되면 아래와 같은 산출물이 하나 나오게 된다.
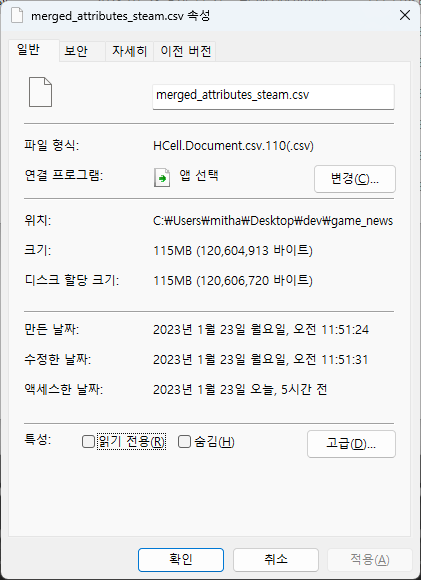
그리고 해당 테이블에 존재하는 열 값의 종류와 정보는 아래의 사진과 같다.

API에서 직접 따온 데이터와 이를 기반으로 새로운 레이블을 만들어냈기에 null값은 존재하지 않음을 알 수 있다.
파일의 사이즈와 크기는 sampling된 개수/플랫폼에 따라 천차만별일 수 있으니 해당 테이블을 직접 크롤링해 보고, 자신에게 맞는 시각화 자료를 만들어보도록 하자.
데이터 가공과 시각화의 매력에 폭 빠져보세요
'개발 > 데이터 분석' 카테고리의 다른 글
| 우리가 분석을 하며 놓치고 있는 것들 - 회귀분석 (0) | 2023.02.04 |
|---|---|
| Kakao 버전 배틀그라운드 유저 데이터 분석해보기[통합] (2) | 2023.01.25 |
| Steam 버전 배틀그라운드 유저 데이터 분석해보기 (2) | 2023.01.21 |
| 배틀그라운드 유저 데이터 분석해보기 4. 데이터 추가 가공 및 시각화 (2) | 2023.01.19 |
| 배틀그라운드 유저 데이터 분석해보기 3. 데이터 가공(+팁) (2) | 2023.01.17 |