4장에서 group by에 대하여 다음과 같은 설명을 한 바 있다.
Select 절에는 group by 절에 기술된 컬럼의 이름(또는 가공된 컬럼)과 집계 함수만 사용되어야 한다.
그 외의 것들이 있을 경우에는 오류를 발생
4장에서 간단하게 짚고만 넘어갔지, 실제 이 '가공된 컬럼'이란 무엇인지에 대해서는 해당 장에서 상세히 짚고 넘어가고자 한다.
가공된 컬럼을 이용한 group by절 응용
앞서 소개한 바와 같이 group by 절에는 기술된 컬럼 외에도 다음과 같은 가공 컬럼이 올 수 있다.
select *, to_char(a_date, 'yyyy') as a_year
from a_table
group by to_char(a_date, 'yyyy');
-- a_date 컬럼의 년도값을 기준으로 그룹핑(사전 존재하는 컬럼을 가공)
이미 존재하는 컬럼에 대한 가공값을 이용하는 예제로 to_char(날짜를 스트링으로 변환)을 이용한 가공 컬럼을 만든 것을 알 수 있다. 이때, 가공되는 값이라 하더라도 해당 테이블의 컬럼값이 포함되어 있어야 하며, 이것만 준수한다면 다양한 방법으로 group by 묶음이 가능하다.
아래의 예시는 1000 단위로 묶어서 표현하는 group by의 예시. floor 함수를 사용하여 소수점 절삭을 응용하였다.
select *, floor(money/1000)*1000 as money_grade, count(*), sum(money)
from a_table
group by floor(money/1000)*1000;추가적으로 N단위로 끊어 범주화 시키고 싶을 때 주로 사용되는 floor 함수.
해당 기능을 사용하기 위해서 floor(컬럼이름/N)*N 을 기술하여 범주화할 수 있다.
여기서 주의사항 한 가지!
group by절을 이용하여 그룹핑한 데이터를 기반으로 추가 가공한 컬럼을 select 하는 건 상관이 없다.
하지만 group by절을 이용하여 그룹핑한 데이터를 임의로 삭제 가공한 컬럼을 select 할 경우 Error
아래와 같은 경우 Error를 출력한다는 의미와 같다.
select *, floor(money/1000) as money_grade, count(*), sum(money)
-- floor 구문을 임의로 변경함
from a_table
group by floor(money/1000)*1000;
group by절을 일종의 원자 단위로 생각하여 절대로 쪼갤 수 없는 값이라 생각하면서 그룹핑을 하자.
Case when이란?
프로그래밍에서의 if/then과 같은 의미로 생각하는 것이 좋다.
아래의 예제는 이름이 '성민'일 경우에만 학번을 출력, 아닌 경우에는 0을 출력시키는 예제이다.
select *, case when name='성민' then 학번 else 0 end
from a_table;
-- 마지막에는 반드시 end 키워드를 넣어줌에 유의
else 절을 비울 경우에는 자동으로 null값을 출력. else문 없이도 case when절 사용이 가능하다.
select *, case when name='성민' then 학번 end
from a_table;
-- 이름이 성민이 아닐 경우에는 null로 처리되는 코드
이걸 여기와서 말하는 이유는? 그룹핑을 진행할 때에도 case when절 사용이 가능하기 때문이다.
아래의 코드는 이름이 성민일 경우에는 'UNIQUE'를, 아닐 경우에는 'OTHERS'로 처리한 뒤 그룹핑하는 코드이다.
select *, case when name='성민' then 'UNIQUE' else 'OTHERS' as HSM
from a_table
group by case when name='성민' then 'UNIQUE' else 'OTHERS' end;여러 범주 중에 몇 개만 특정하고 나머지는 퉁치고 싶을 때 유용하게 사용할 수 있는 기능일 듯싶다.
case when을 이용한 피봇팅(Pivoting)
group by를 진행할 때 행 레벨로 만들어진 데이터를 열 레벨로 전환하고 싶을 때 집계 함수와 case when을 적절히 결합하여 사용한다.
년도와 달을 기준으로 가격을 설정하고 싶을 때 아래와 같은 코드를 사용한다 가정
select year, month, sum(price), as sum_price
from a_table
group by year, month; -- 년월을 기준으로 그룹핑
이를 컬럼 레벨로 Pivoting 하고 싶을 때 아래와 같은 코드를 사용
select year, sum(price) as sum_price
, sum(case when month=1 then price end) as Jan
, sum(case when month=2 then price end) as Feb
-- 이하 생략
, sum(case when month=12 then price end) as Dec
from a_table
group by year;
여기서 헷갈릴 수 있는 함수의 특징
count 함수는 0과 1 여부에 상관없이 값이 존재만 한다면 무조건 1로 계산하는 특징을 가진다.
select count(case when name='성민' then 1 else 0 end) as count
from a_table위와 같이 실행하여도 모든 값이 카운트되어 출력됨에 유의하자!
해당 count를 정상적으로 작동시키기 위해서는 이외의 값을 null로 처리해 주거나, 상기 코드를 sum으로 실행하여야 한다.
select sum(case when name='성민' then 1 else 0 end) as count -- 실행 예제 1
,count(case when name='성민' then 1 end) as count -- 실행 예제 2
,count(case when name='성민' then 100 end) as count -- 이것도 실행...은 되는 예제 3
from a_tablegroup by rollup과 cube
각 키워드는 group by와 같이 사용되어 group by절에 사용되는 컬럼에 대하여 추가적인 group by를 진행할 수 있게 한다.
이때 rollup은 계층적인 방식으로 group by를 추가적으로 시행하고, cube는 group by절에 기재된 컬럼들의 가능한 조합으로 group by절을 추가적으로 시행하는 차이를 가진다.
rollup
두 개 이상의 컬럼을 이용한 계층적 group by. 대표적으로 그룹에 대한 소계(도중도중 합계 출력)를 만들고 싶을 때 주로 사용한다.
select stu_floor, grade, sum(price)
from a_table
group by rollup(stu_floor, grade) -- stu_floor를 우선 그룹핑 시킨 뒤 grade를 계층적으로 그룹핑
order by 1,2;
-- 그룹핑의 진행은 (stu_floor, grade) -> (stu_floor) -> ()
-- 만약 (1,2,3) 순서라면 그룹핑의 진행은 (1,2,3) -> (1,2) -> (1) -> ()select에 sum(price)에 대하여 stu_floor+grade에 대한 그룹핑 진행 후 각 그룹에 대한 price 총합이 나올 것이고, 그 뒤에는 stu_floor에 대해서만 그룹핑 진행 후 그룹에 대한 price 총합이 나올 것이다.
예시에 대한 다른 코드로 타 블로그에서 정리가 잘 된 코드와 이미지가 있어 같이 소개해보도록 한다.
select 상품ID, 월, sum(매출액) as 매출액
from 월별매출
group by rollup(상품ID, 월);아래는 상기 SQL를 시행한 결과이다.

그룹핑이 계층적으로 이루어지는 것을 확인할 수 있다.
cube
cube에 나열된 컬럼들의 가능한 모든 조합으로 그룹핑을 진행함
select stu_floor, grade, sum(price)
from a_table
group by cube(stu_floor, grade) -- stu_floor를 우선 그룹핑 시킨 뒤 grade를 계층적으로 그룹핑
order by 1,2;
-- 그룹핑의 진행은 (stu_floor, grade) -> (stu_floor) -> (grade) -> ()결과 컬럼이 rollup에 비해서 굉장히 난잡해지는 특성. 실제로 cube의 레벨이 3개 이상으로 늘어날 경우 대환장 파티가 일어난다고 한다.
아래는 기존 rollup의 코드를 cube로만 변환하고 실행된 결과를 나타내고 있다.
select 상품ID, 월, sum(매출액) as 매출액
from 월별매출
group by cube(상품ID, 월);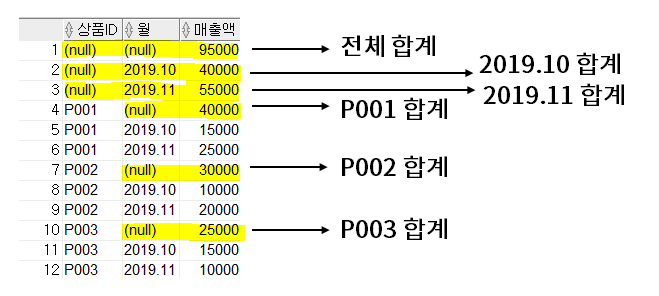
결과가 모든 조합에 대하여 나타나고 있음을 확인할 수 있다.
위 특징을 명시적/이론적으로 살펴보도록 하자. group by절의 나열된 컬럼 수가 N개라면?
1. rollup을 사용할 경우 group by는 N+1회를 수행한다.
2. cube를 사용할 경우 group by는 N^2회를 수행한다.
코드의 일관성을 위해, 또는 사람의 시각적 용이성을 위해 어떠한 방식으로 보여주는 것이 유리할지 끊임없이 고민하고 생각해 보자.
'개발 > 기타 개인 공부' 카테고리의 다른 글
| 게임이 가져야 하는 6가지 요소 (0) | 2023.02.06 |
|---|---|
| SQL 기본 6. 서브 쿼리(Subquery, Where 절) (0) | 2022.12.29 |
| SQL 기본 4. 그룹/집계 함수의 이해 (2) | 2022.12.21 |
| SQL 기본 3. 시간 정보와 추출(Date, Timestamp, Time, Interval) (0) | 2022.12.20 |
| SQL 기본 2. Outer/Non Euqi Join (0) | 2022.12.19 |