Join은 관계형 데이터베이스에서 가장 기본이자 중요한 기능
두 개 이상의 테이블을 서로 연결하여 데이터를 추출하는 과정을 의미한다.
관계형 데이터베이스에서는 Join을 통해 서로 다른 테이블간 정보를 원하는 만큼 가져올 수 있는 장점이 있다.
어떻게든 연결만 된다면 = 공통 Key값이 존재한다면 이 둘을 합쳐 새로운 테이블을 만들 수 있다는 것은 가장 큰 강점임
여기서 가져갈 수 있는 특징 한 가지!
💡 Join 하려는 각 테이블의 위치관계는 동등하다. 이는 두 테이블의 크기에 차이가 있다 하더라도 상호간의 정보를 교환할 수 있는 특징을 가진다고도 할 수 있다.

💡 여기서 유일하지 않은 테이블 A와 각 키값이 유일한(unique) 테이블 B가 있을 때 이 둘의 Join 결과 집합은 A 집합의 레벨을 그대로 유지함을 알고 있어야 한다.
(=1:M Join 시 결과 집합은 M집합의 레벨을 그대로 유지된다는 특징)
위의 내용처럼 unique한 테이블을 1. 유일하지 않은 키값들을 가진 테이블을 M이라 하여 해당 내용의 Join을 1:M Join이라고도 부른다.
만약 A집합의 레벨이 아닌 다른 레벨로 변경하고 싶을 경우에는 SQL 구문의 group by 키워드를 사용하여 변경할 수 있다. 하지만 이때의 select 구문은 aggregation을 제외하고 해당 레벨만을 담아야 함에 유의한다.
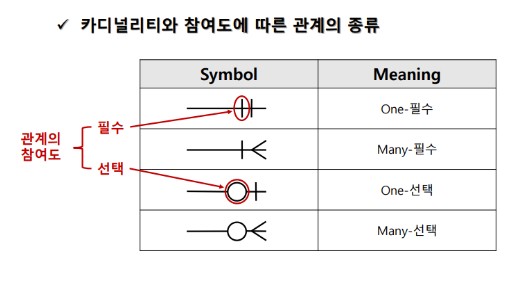
1:M 관계는 상기 그림에서의 2, 4번째 그림이 표시하는 Symbol이라고도 할 수 있을 것 같다.
해당 관계에 대해서는 부모-자식 관계라는 표현을 많이 쓰기도 하는데, 두 테이블이 동등하다는 특징에서 자칫 종속성을 띨수도 있다는 어폐가 생길 수 있음. 이해를 위해 쓰는 표현임을 알고 넘어가자.
이와 비슷한 개념으로 M:N Join에서는 결과 집합의 크기가 M*N개라는 것에서 차이를 가진다.
하지만 비즈니스적인 관계적으로 1:M 관계가 거의 대다수이기 때문에, M:N 관계를 직접적으로 설명하는 것보다는 M과 N 사이의 공통점 한 가지를 찾아 M:1:N = 1:M으로 풀어서 이해하는 것이 유리하다.
아무것도 이야기하는 것 없이 Join이라고 하면 Inner Join이라고 생각하는 것이 좋을 것.
다른 Join에 대해서는 추후에 공부하도록 하자.
몇 가지 SQL을 공부하면서 처음 보는 키워드
BETWEEN : 이상과 이하를 말하는 데 사용되는 키워드
-- 상기 생략
b.table_b between to_date('19970101','yyyymmdd') and to_date('19971231','yyyymmdd')
TO_DATE : 날짜의 형변환
처음 사용했을 때의 포맷은 'yyyymmdd'만 사용했지만, 'yyyy/mm/dd' 형식으로도 사용이 가능한 것으로 보인다.
to_date('19970101','yyyymmdd') 시 1997-01-01이라는 날짜형 타입으로 반환됨
SELECT 구문에서도 concat + as를 이용하여 새로운 컬럼을 생성하는 것이 가능하다.
concat의 키워드는 ||을 사용하며, 이를 이용하여 아래와 같은 컬럼 생성이 가능
select a.first_name||' '||a.last_name as full_name
'개발 > 기타 개인 공부' 카테고리의 다른 글
| SQL 기본 6. 서브 쿼리(Subquery, Where 절) (0) | 2022.12.29 |
|---|---|
| SQL 기본 5. Group by 응용(가공 컬럼, case when/rollup/cube) (2) | 2022.12.22 |
| SQL 기본 4. 그룹/집계 함수의 이해 (2) | 2022.12.21 |
| SQL 기본 3. 시간 정보와 추출(Date, Timestamp, Time, Interval) (0) | 2022.12.20 |
| SQL 기본 2. Outer/Non Euqi Join (0) | 2022.12.19 |